本地AI模型
本地AI模型翻译指将翻译模型完全部署在用户设备本地,不依赖网络,所有数据处理均在设备端完成。这种方式更适合注重隐私安全、响应速度和自定义能力的用户。
硬件要求与显卡选择
由于大语言模型在推理过程中需要高强度的并行计算并占用大量显存,因此注意:
- N卡用户: 建议使用 RTX 3060 12GB 及以上型号。显存大小至少需 6GB 起步。
- A卡用户:目前仅支持 RX 7900 / 7800 / 7700 / 6900 / 6800 / 6700 系列显卡。
- 必看: 模型在运行过程中需要预留 1-2GB 的空闲显存以维持系统稳定。因此,8GB 显存及以下的用户,在模型运行期间请务必关闭 3A 游戏、建模渲染、视频剪辑等高负荷显卡应用,避免崩溃。
优先选择基于 llama架构 的模型,兼容N卡与A卡且易于部署
目前支持的本地模型包括:
- Sakura(llama 架构)
- Sakura(tgw 模型分支)
操作说明:
- 检查自己的显卡运行配置以作合适选择,查看方法
- 下载llama或tgw模型启动器和AI模型文件,下载方法
- 运行启动器并且加载好模型,运行方法
- 进入团子翻译器的
设置面板,点击【翻译源设定】,选择【本地AI翻译】; - 点击【测试】按钮,验证一次翻译是否可用;
- 测试成功后,回到
本地AI翻译界面,打开设置项的【开关】。可同时打开多个配置项开关。
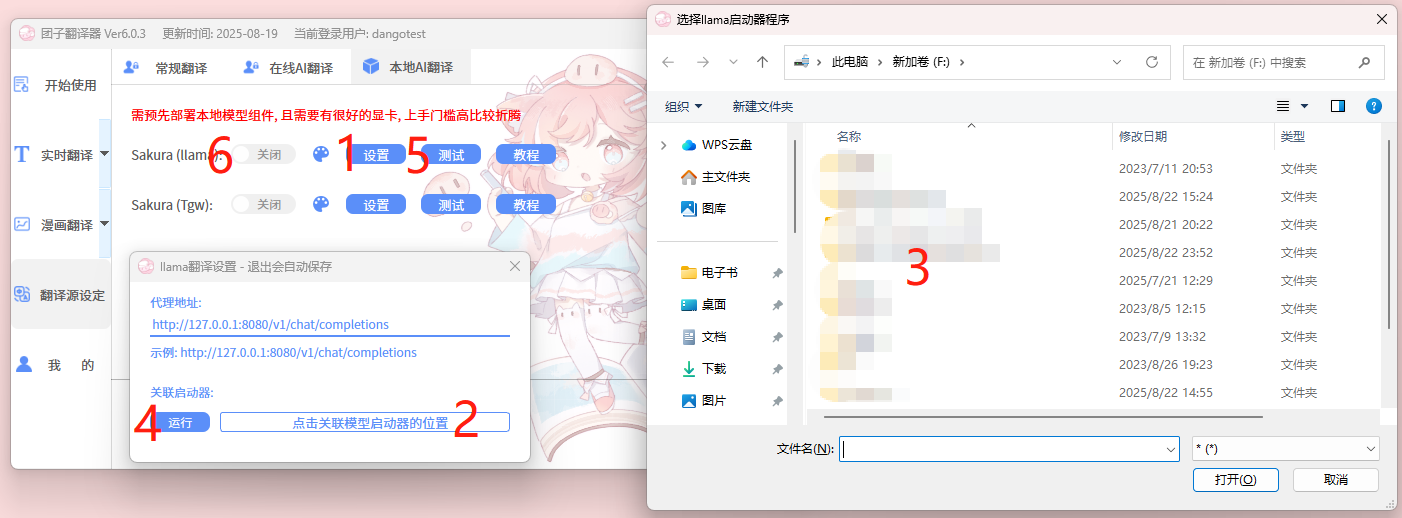
代理地址参数说明:
- Sakura(llama ) 启动器默认地址:http://127.0.0.1:8080/v1/chat/completions
- Sakura(tgw ) 启动器默认地址:http://127.0.0.1:5000/v1/chat/completions