本地部署
本地部署模型对电脑显卡要求较高,建议N卡3060/A卡Rx 6700XT以上,若对翻译要求较高且配置不足的,可以考虑租用显卡方案
网盘提供本目录全部文件。
查看电脑是否支持运行本地翻译模型
在系统任务栏底部右键,点击
任务管理器(或直接按Ctrl + Shift + Esc快速打开)
点击
性能,GPU0(如果存在多个GPU,选择更下面的那个),查看专用GPU内存大小,如图为12G显存,就满足了模型运行要求的最低6G显存,否则移步至在线AI翻译源

本地翻译模型说明
本翻译源需要一定电脑操作基础不推荐新手使用
Sakura 指模型名称,需要通过启动器运行(SakuraLLM / TGW),推荐使用 SakuraLLM。
模型选择建议
显存大小 推荐模型 场景 6GB - 8GB 4B(Sakura-GalTransl-v4-4B/Gemma-3-4b-it) 轻度游戏和日常翻译 7B(Sakura-GalTransl-7B-v3.7) 小说、文档、漫画 8GB及以上 14B(Sakura-Galtransl-14B-v3.8/Gemma-3-12b-it) 小说、文档、漫画 Sakura模型只能用于日语翻译,Gemma模型属于通用模型,可以翻译主流语种及部分小语种
如链接失效请移步网盘
Sakura(llama)教程
确认电脑支持运行并下载本地翻译模型;
下载 Sakura 启动器:
请在下方任一链接中,下载
Sakura_Launcher_GUI_v1.2.0-beta.exe文件。强烈推荐使用网盘下载!本教程所需的所有文件(包括启动器、依赖库)均已整合在网盘中,文件名为
Sakura_Launcher_GUI_v1.2.0。下载并解压后,您可以直接跳至第 5 步
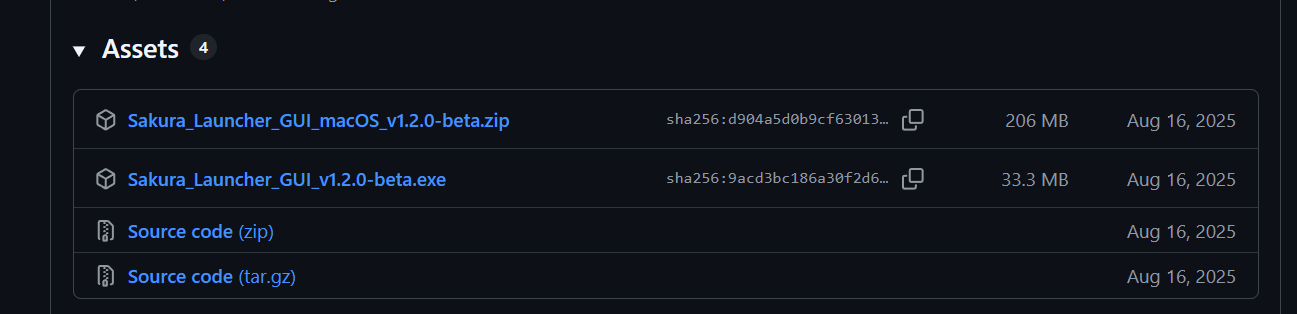
下载llama文件cudart-llama-bin-win-cuda-13.1-x64.zip和llama-b8339-bin-win-cuda-13.1-x64.zip,进行解压。注意Cuda版本号保持一致!
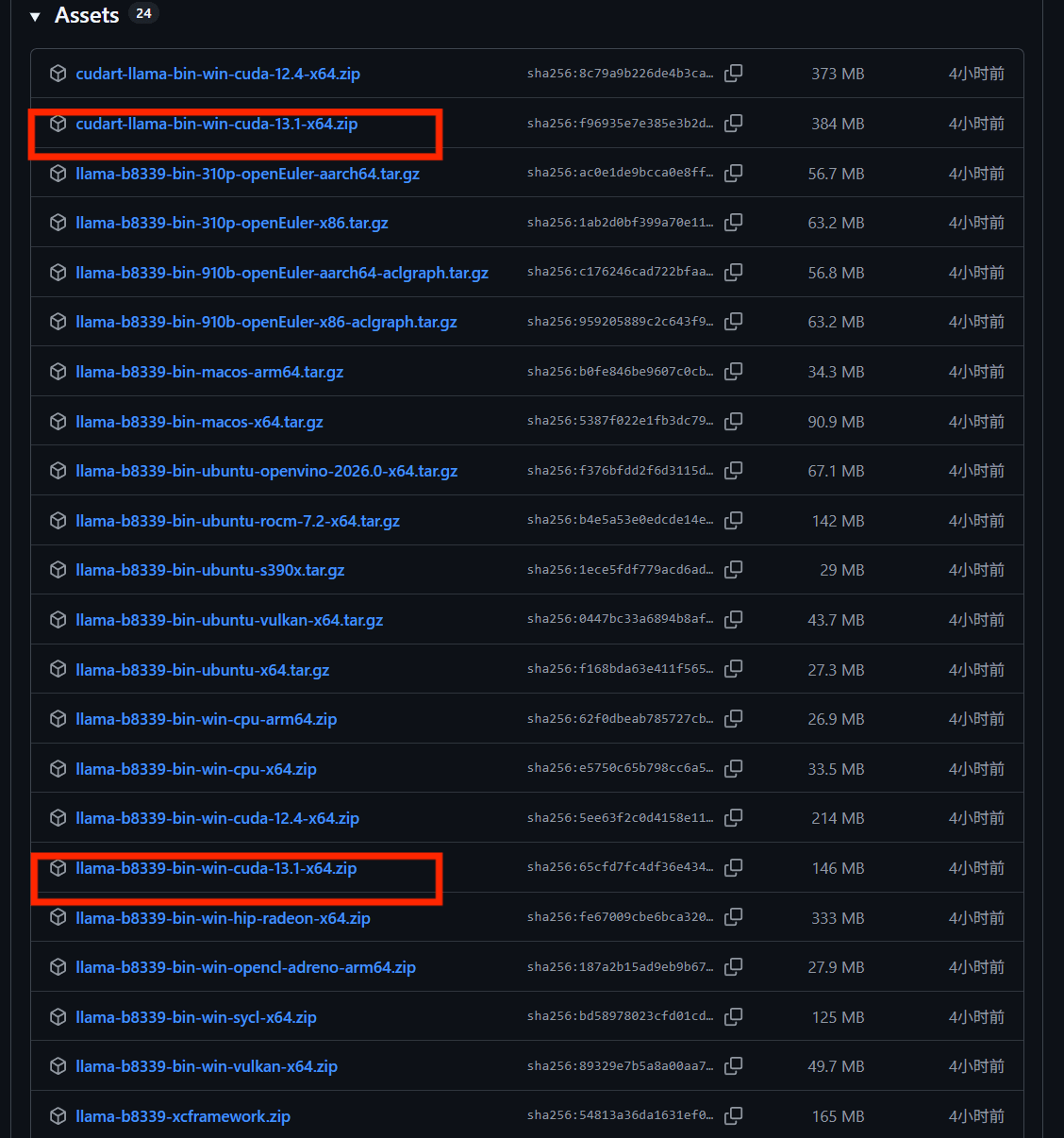
随后将解压出来的 cudart-llama-bin-win-cuda-13.1-x64 文件夹中的三个文件,拖入至 llama-b8339-bin-win-cuda-13.1-x64 文件夹内。完成替换后,将该文件夹重命名为 llama。
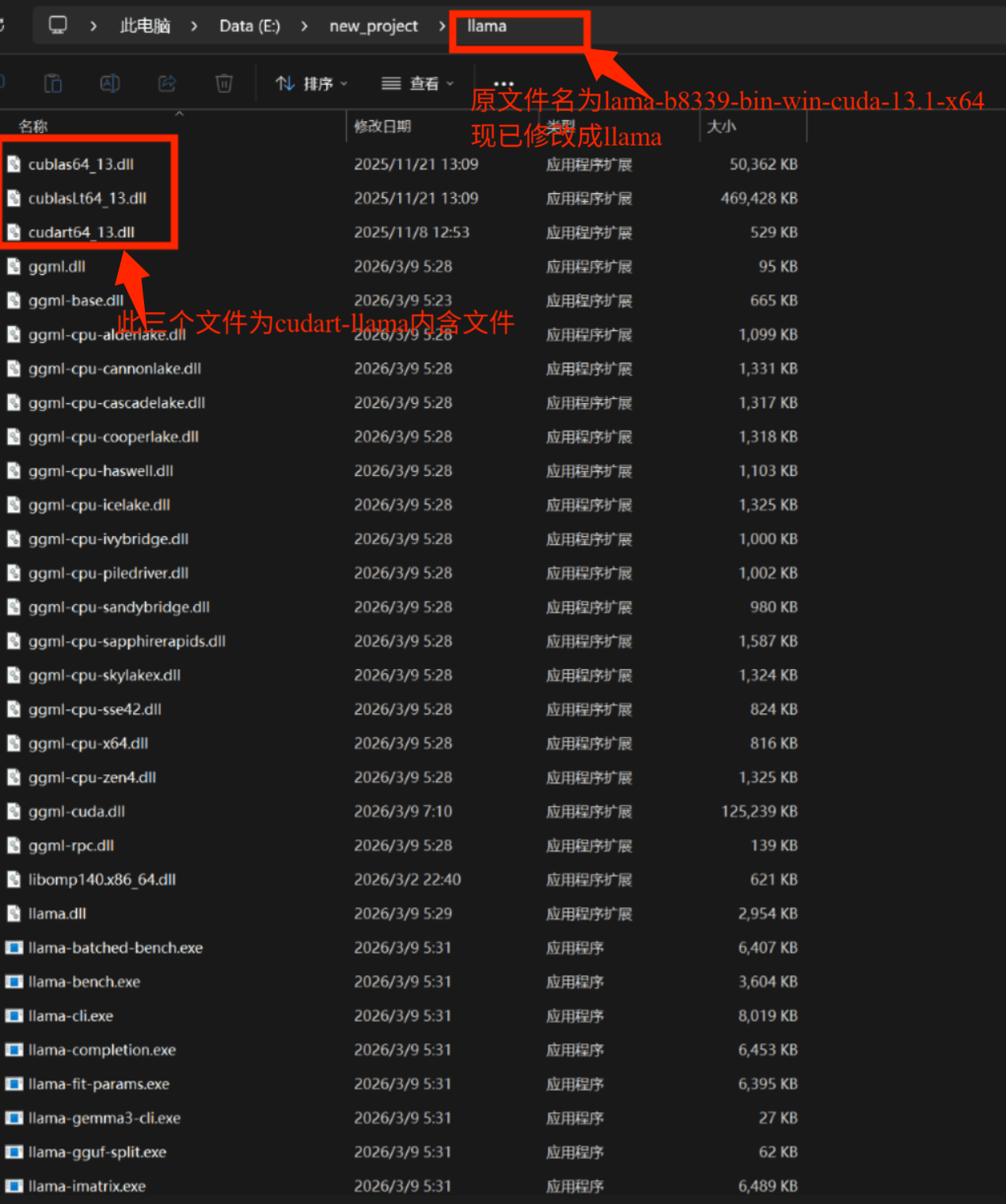
随后将下载好的翻译模型,启动器,llama文件放置在同一路径文件夹
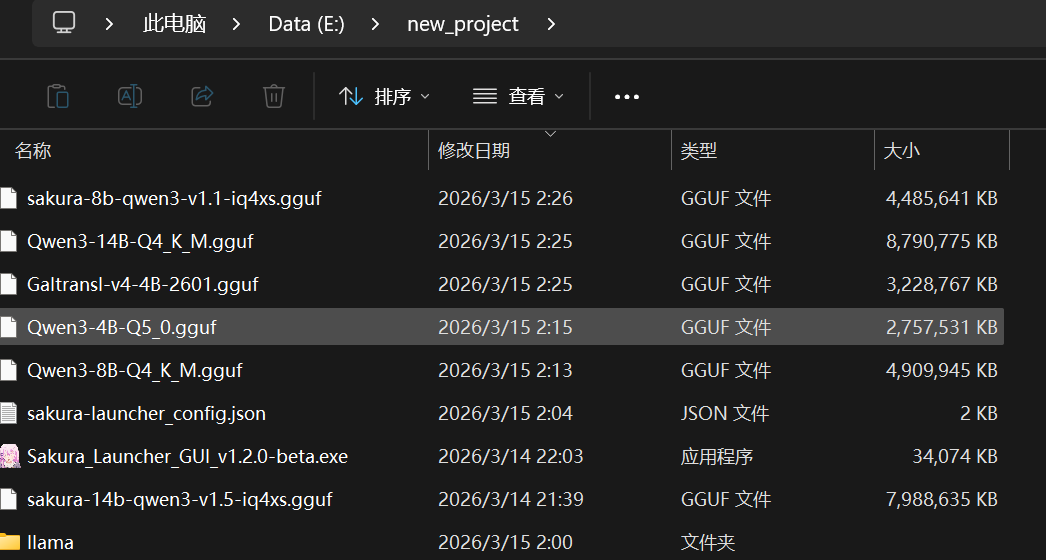
启动Sakura_Launcher_GUI_v1.2.0-beta.exe文件,选择你需要加载的翻译模型和显卡后,将上下文调成2048,并发数量调成2
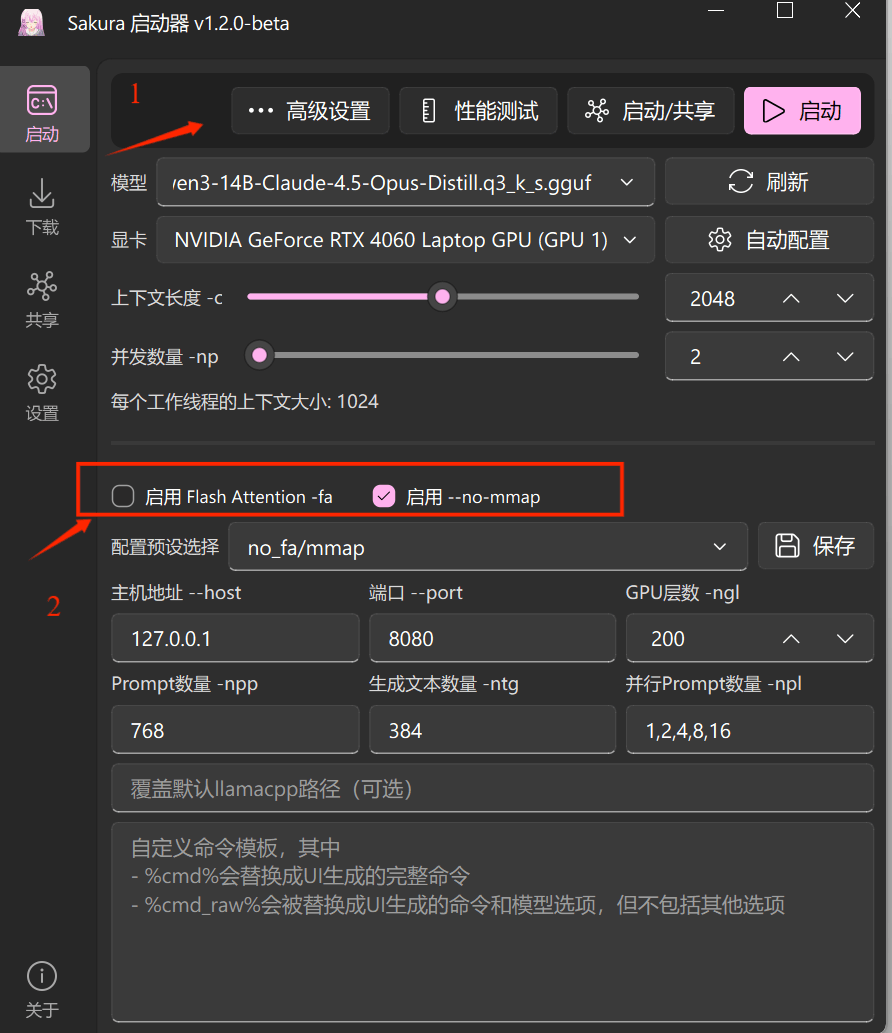
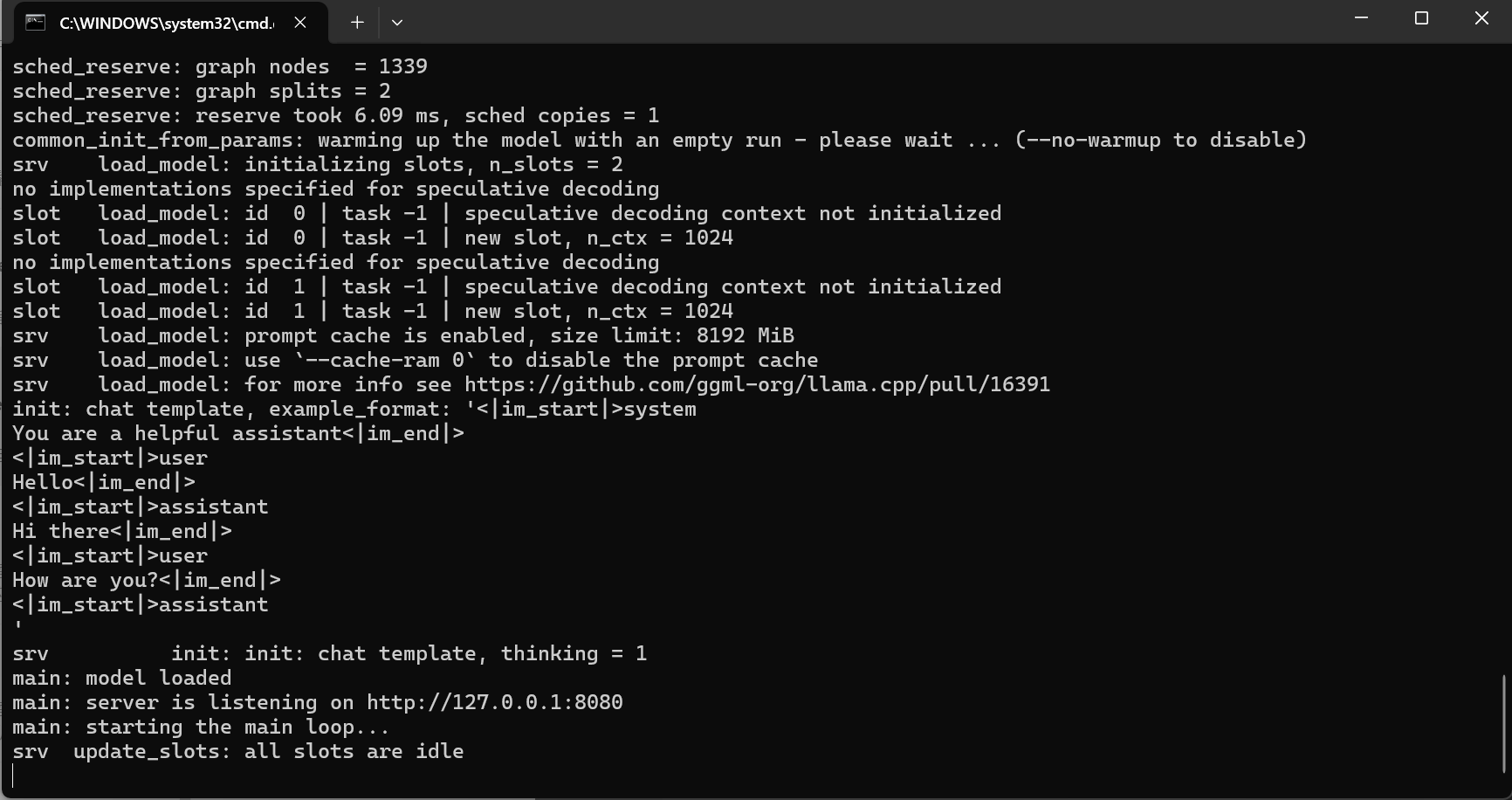
点击启动,当黑色命令行窗口显示以下内容时,代表模型已成功启动。注意:在翻译期间请勿关闭此黑窗,否则会中断翻译服务。如果出现报错或其他内容,请加入团子翻译器交流群寻求解答。
团子翻译交流群号:434137389
TGW部署教程
部署和安装教程很长,具体可参考tgw部署视频
确认tgw完成部署并运行模型后,点击测试,看能否正常运行